The Scaling Trap: When Pilots Become Infrastructure
AI pilots are designed to succeed. They operate under favorable conditions — curated data, limited scope, dedicated attention, engaged stakeholders. When a pilot produces positive results, the organization treats the outcome as validation. It is not validation. It is a demonstration under controlled conditions that have no structural relationship to production reality.
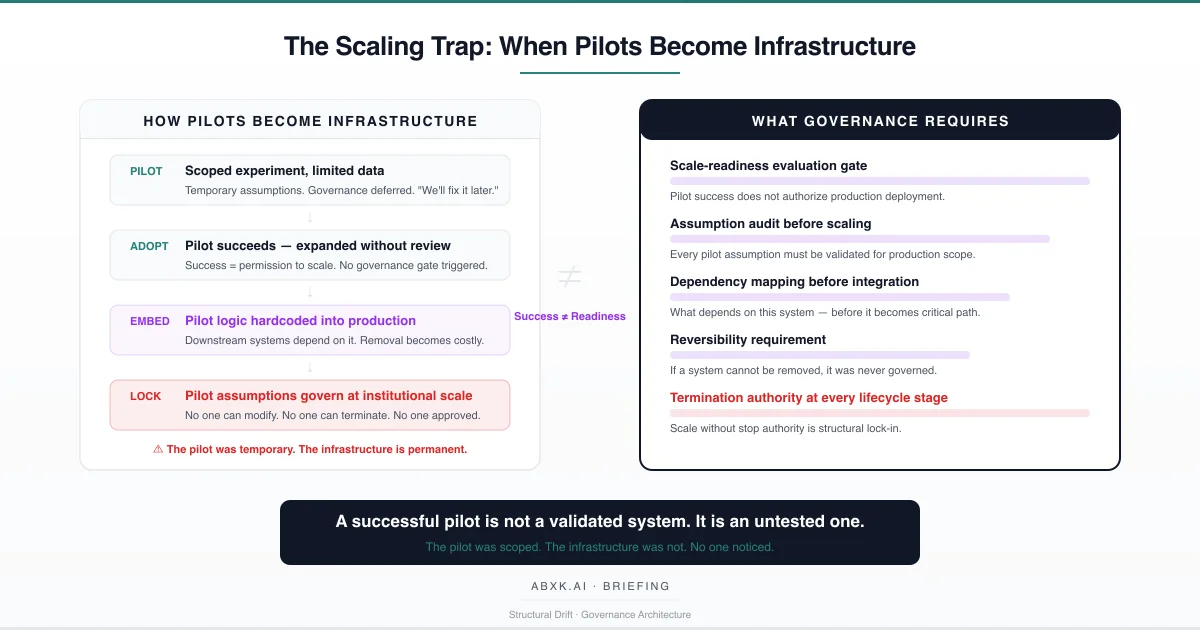
The scaling trap occurs at the transition point. A pilot succeeds. The organization decides to scale. No governance gate evaluates whether the assumptions that enabled pilot success hold at production scope. No evaluation framework assesses whether the system’s architecture, data dependencies, and operational requirements are structurally prepared for institutional integration. The pilot’s logic — designed for experimentation — becomes embedded in production infrastructure. The temporary becomes permanent. The scoped becomes institutional.
This is not a deployment decision. It is a governance failure.
AI Governance defines how systems transition from experimental validation to production authority. Without governance architecture at the scaling boundary, pilot assumptions migrate into institutional infrastructure without review, without accountability, and without reversibility. The organization scales the output. It does not scale the governance.
The scaling trap does not fail at the technical layer. It fails at the decision layer — where organizations confuse pilot success with production readiness, and where no structural gate separates experimentation from institutional commitment.
Understanding that distinction is central to AI Risk Management, AI Security, and Responsible AI implementation in production environments.
The Technical Foundations of Pilot Fragility
Pilots succeed for reasons that are structurally distinct from the reasons production systems must succeed. Understanding this distinction requires examining what pilot conditions actually validate — and what they do not.
Data conditions. Pilots typically operate on curated, cleaned, or limited datasets. The data is representative of the problem the pilot was designed to address, but not representative of the full distributional complexity the system will encounter at scale. Edge cases are underrepresented. Adversarial inputs are absent. Data quality reflects the attention of the pilot team, not the reality of production data pipelines. When the system scales, data quality degrades — not because the data worsens, but because the curation that sustained the pilot does not scale with it.
Scope conditions. Pilots operate within defined boundaries: a single use case, a specific user group, a limited geographic or operational context. These boundaries constrain the range of inputs the system encounters and the range of outputs it must produce. At scale, boundaries expand. The system encounters input distributions it was never validated against. Output is consumed by stakeholders and systems that were not part of the pilot evaluation. The scope that made the pilot manageable becomes the assumption that makes production unreliable.
Attention conditions. Pilots receive disproportionate organizational attention. Subject matter experts review output carefully. Engineers monitor system behavior closely. Stakeholders provide feedback actively. This attention creates an implicit quality layer that is not part of the system’s architecture — it is a function of organizational investment in the experiment. When the system scales, the attention dissipates. Review becomes cursory. Monitoring becomes automated. The quality layer that supported pilot accuracy is removed without being replaced by governance architecture.
Statistical conditions. Models validated at pilot scale may exhibit acceptable performance metrics — accuracy, precision, recall — that reflect the pilot’s limited distributional scope. These metrics do not transfer reliably to production conditions where the input distribution is broader, more variable, and subject to calibration drift, concept drift, and feature instability. A model that performs well on a carefully selected dataset has been validated for that dataset, not for the operational environment it will inhabit.
Pilot success is conditioned on pilot conditions. When those conditions are removed — as they inevitably are during scaling — the success is no longer structurally guaranteed. The results remain in organizational memory. The conditions that produced them do not.
Structural Fragility at the Scaling Boundary
The structural fragility of the scaling trap does not reside in the pilot’s performance. It resides in the absence of evaluation architecture at the boundary between pilot and production.
In most organizations, the decision to scale an AI pilot is treated as an operational decision — a resource allocation choice, a deployment timeline, a capacity expansion. It is not treated as a governance event. No formal assessment evaluates whether the pilot’s assumptions hold at production scope. No structural audit identifies which conditions enabled pilot success and which of those conditions will not persist at scale. No reversibility assessment determines whether the scaled system can be suspended, modified, or removed if its assumptions fail.
The fragility compounds through integration depth. A pilot that operates as a standalone experiment has limited blast radius. A pilot that is scaled into production architecture — connected to data pipelines, integrated with downstream systems, embedded in operational workflows — acquires dependencies that make removal structurally difficult. Each integration point increases the cost of reversal. Each dependency reduces the organization’s ability to exercise termination authority.
This creates an irreversibility gradient. Early in the scaling process, the system can be paused or removed with minimal disruption. As integration deepens, removal becomes operationally prohibitive. The organization reaches a point where it is cheaper to operate a system built on unvalidated pilot assumptions than to remove it and rebuild on validated foundations. The scaling trap is complete. The pilot’s temporary logic governs at institutional scale.
The number remains. The meaning changes. The assumptions were never audited.
Organizational Failure Patterns
Organizations that scale AI pilots without governance architecture exhibit specific, identifiable failure patterns. These patterns are structural — they emerge from the absence of evaluation gates, not from individual decision-making errors.
Success bias. The most consequential failure pattern is using pilot success as authorization for scaling. In governance terms, a successful pilot demonstrates that a system works under controlled conditions. It does not demonstrate that the system is ready for production conditions. But organizations routinely treat pilot success as sufficient justification for scaling — because the alternative (conducting a rigorous scale-readiness evaluation) introduces delay, cost, and organizational friction. Success becomes permission. Permission bypasses governance.
Assumption inheritance. Pilots are built on explicit and implicit assumptions — about data quality, input distribution, user behavior, integration requirements, and review capacity. These assumptions are rarely documented because the pilot is understood as temporary. When the pilot scales, the assumptions scale with it — but they are no longer visible. The organization inherits assumptions that were appropriate for experimentation and treats them as valid for production. The assumptions were never wrong at pilot scale. They are wrong at production scale. And no one audited the transition.
Governance deferral. Organizations frequently acknowledge that pilot systems require governance review before production deployment — and then defer that review under operational pressure. The pilot works. Stakeholders want results. The business case supports scaling. The governance review becomes a planned-but-unscheduled activity that is overtaken by integration timelines. By the time governance review is conducted — if it is conducted — the system is already embedded in production. The review becomes retroactive documentation rather than prospective evaluation.
Dependency accumulation. As a scaled pilot integrates with production systems, it acquires dependencies that are not governed. Downstream systems begin consuming its output. Reporting layers incorporate its metrics. Operational workflows embed its logic. Each dependency is created independently, without coordination, and without governance assessment of the cumulative integration risk. The pilot — now an infrastructure component — has become structurally necessary before it was structurally validated.
Termination incapacity. The ultimate failure pattern is the loss of termination authority. An organization that has scaled a pilot into production infrastructure, accumulated downstream dependencies, and built operational workflows around its output may discover that the system’s assumptions are invalid — and be unable to act. Removing the system would disrupt operations. Modifying it would require re-engineering dependent systems. The organization lacks the structural capacity to terminate a system that should never have been scaled without evaluation.
These are governance failures — not tooling failures. The pilot functioned as designed. The organization failed to govern the boundary between experimentation and institutional commitment.
AI Security Implications
The scaling trap creates security vulnerabilities that compound with integration depth.
A pilot operating in a controlled environment has a limited attack surface. Its data sources are known. Its integration points are minimal. Its output consumers are identifiable. When the same system scales into production infrastructure, every dimension of its attack surface expands. Data sources multiply. Integration points proliferate. Output consumers include systems and stakeholders that were never part of the pilot’s security assessment.
Security architecture designed for pilot conditions — scoped access controls, limited data exposure, minimal integration surface — does not scale automatically. The security posture that was adequate for experimentation becomes structurally insufficient for production. But the organization rarely conducts a security reassessment at the scaling boundary, because the scaling decision is treated as operational rather than architectural.
The vulnerability is compounded by assumption inheritance. Experimental-grade security assumptions — that data is clean, that inputs are benign, that adversarial pressure is minimal — become embedded in production systems that face adversarial conditions, data contamination, and exploitation attempts that the pilot never encountered. The security model was valid for the pilot’s scope. It is not valid for the system’s actual exposure. At scale, pilot-era data handling assumptions become production-era exposure if data boundaries were never governed.
Where scaled pilot output has migrated into operational standards or institutional policy, the security implications extend beyond the system itself. Compromising a prototype-grade system that governs institutional decisions is functionally equivalent to compromising institutional policy — with the additional vulnerability that pilot-grade security controls may lack the resilience to withstand production-level adversarial pressure.
Compliance and Accountability Implications
Compliance frameworks require that production systems operate under validated conditions. The scaling trap structurally undermines that requirement.
A pilot that was validated for experimental conditions and scaled without re-evaluation operates outside its validation boundary at production scope. The compliance documentation reflects pilot conditions — the limited dataset, the controlled scope, the curated inputs. The production system operates under conditions that the documentation does not describe and the validation did not cover. Compliance becomes structurally incomplete — not because documentation is missing, but because the documented validation does not correspond to the system’s actual operating environment.
Auditability requires traceability from production decisions to validated system parameters. When a pilot is scaled without governance review, that traceability is broken. Audit processes that trace decisions to system output cannot verify that the system was validated for the conditions under which those decisions were made. The audit trail is intact. The validation chain is not.
Proportionality obligations require that the scope and impact of automated decisions be proportionate to the governance architecture that governs them. A pilot-grade system governing institutional decisions operates with disproportionate impact relative to its governance architecture. The system’s influence has scaled. The governance has not.
Accountability assignment becomes ambiguous when pilot systems scale without governance authorization. Who is accountable for decisions made by a system that was never formally approved for production deployment? The pilot team designed it for experimentation. The operations team deployed it for convenience. The governance function was never consulted. Accountability belongs to no one because the scaling decision occurred outside every formal authority structure.
Compliance is operational enforceability — not documentation. And enforceability requires that every production system was validated for production conditions, authorized for production deployment, and governed under production accountability.
Production-Environment Reality
In production environments, the scaling trap is accelerated by conditions that create structural pressure to scale without evaluation.
Integration pressure. Production systems operate under continuous integration pressure — the demand to connect new capabilities with existing infrastructure as rapidly as possible. Pilot systems that demonstrate value are immediately subject to integration requests from downstream teams. Each integration creates operational dependency before governance evaluation occurs. The pilot becomes infrastructure through integration, not through authorization.
Transformation chains. When pilot output enters production data pipelines, it undergoes transformations — normalization, aggregation, reformatting — that obscure the pilot’s conditional nature. By the time the output reaches decision-makers or downstream systems, it carries the authority of production data rather than the conditionality of experimental inference. The transformation chain strips the pilot’s provisionality.
Hybrid workflows. Production environments blend human and automated decisions across multiple systems. A pilot scaled into a hybrid workflow becomes one component in a decision chain where its experimental status is invisible to the other components. The workflow functions. The governance gap is undetectable from within the process.
Model versioning. When a pilot-grade model is updated or retrained for production scale, the version transition may alter its behavior in ways the pilot validation did not anticipate. The organization assumes continuity between the pilot version and the production version. The statistical basis may have changed. The behavioral continuity is assumed, not verified.
Vendor dependency. Pilots built on external vendor components — APIs, models, platforms — inherit vendor assumptions that may change without notice. When the pilot scales, vendor updates alter the foundation of the production system. The organization’s scaled system drifts not because of internal changes, but because the vendor’s component evolved independently.
Monitoring obligations at production scale must include pilot-assumption tracking: continuous verification that the conditions which validated the pilot remain valid at production scope. This is not standard model monitoring. It is assumption lifecycle monitoring — a governance obligation that most organizations do not recognize because the scaling decision never triggered a governance review.
Governance Architecture for the Scaling Trap
Governing the pilot-to-production transition requires structural controls at the scaling boundary. The following architecture components represent the structural minimum for organizations that operate AI pilots with potential for production deployment.
Scale-readiness evaluation gate. Before any pilot transitions to production, a formal evaluation gate must assess whether the pilot’s assumptions, data conditions, scope conditions, and attention conditions hold at production scale. The gate must be a governance event — requiring authorization from domain owners, risk functions, and technical leadership. Pilot success does not authorize scaling. Governance evaluation authorizes scaling.
Assumption audit. Every pilot operates on assumptions — explicit and implicit. Before scaling, those assumptions must be identified, documented, and evaluated for production validity. Assumptions that held at pilot scope — about data quality, input distribution, review capacity, and integration requirements — must be re-validated against production conditions. Assumptions that do not hold must be addressed before scaling proceeds.
Dependency mapping. Before a pilot integrates with production systems, the organization must map every downstream dependency the integration will create. Dependency mapping must identify what systems, workflows, and decisions will consume the pilot’s output — and what the consequence of output degradation or system suspension would be at each dependency point.
Reversibility requirement. Every scaled system must retain the ability to be suspended, modified, or removed without cascading operational failure. If scaling a pilot into production creates irreversible dependencies, the scaling decision must include explicit authorization for that irreversibility — including accountability for the consequences of operating an unvalidated system that cannot be terminated.
Escalation architecture. When a scaled system exhibits behavior that diverges from pilot performance, escalation paths must route the divergence to governance review. Divergence detection requires monitoring not only system performance metrics but the validity of the pilot assumptions under production conditions.
Decision authority assignment. For every scaled system, the organization must assign explicit decision authority: who authorized the scaling, who monitors production validity, who can mandate recalibration, and who can terminate the system. Decision authority must be named and documented. Unnamed authority is absent authority.
Documentation and traceability. The governance record must trace every scaled system to its pilot origin, its assumption audit, its scale-readiness evaluation, its dependency map, and its authorization chain. Undocumented scaling is ungoverned scaling.
Continuous assumption review. Pilot assumptions that were valid at the moment of scaling may degrade over time. Organizations must conduct periodic reviews of the assumptions that justified scaling — verifying that they remain valid under current production conditions. Assumption degradation that is not detected is assumption failure that is not governed.
This framework does not eliminate scaling risk. It prevents scaling risk from becoming institutional failure.
Doctrine Closing
The scaling trap is not a deployment error. It is a governance architecture gap at the boundary between experimentation and institutional commitment.
Pilots succeed because they are designed to succeed — under curated conditions, limited scope, and concentrated attention. Scaling removes those conditions. What remains is pilot-grade logic operating at institutional scale, governing decisions it was never validated to inform.
The scaling trap is not a tooling problem. It is a governance architecture problem. Governance does not prevent organizations from scaling successful pilots. It prevents organizations from scaling unvalidated assumptions into irreversible infrastructure.