Human-in-the-Loop Is Not a Control Strategy
Organizations deploy AI systems with human reviewers positioned at critical decision points. A compliance analyst reviews AI-generated risk assessments. A content moderator evaluates AI classification outputs. A loan officer examines AI credit recommendations. A clinician reviews AI diagnostic suggestions.
In each case, the organization describes this arrangement as human oversight. The human is in the loop. The system does not act autonomously. A person reviews every output before it becomes a decision.
The structural question is not whether a human is present. It is whether the human can actually control the system’s behavior.
In most production AI environments, the answer is no. The human reviewer lacks the authority to override the system, or possesses nominal authority that produces no operational effect. The reviewer lacks the cognitive capacity to evaluate the volume and complexity of outputs the system generates. The reviewer lacks the information needed to assess whether the system’s output is appropriate — because the system’s reasoning is opaque, its confidence is uncalibrated, and its failure modes are undocumented. The reviewer lacks structured escalation paths — when the output seems wrong, there is no defined mechanism to halt the system, investigate, and remediate.
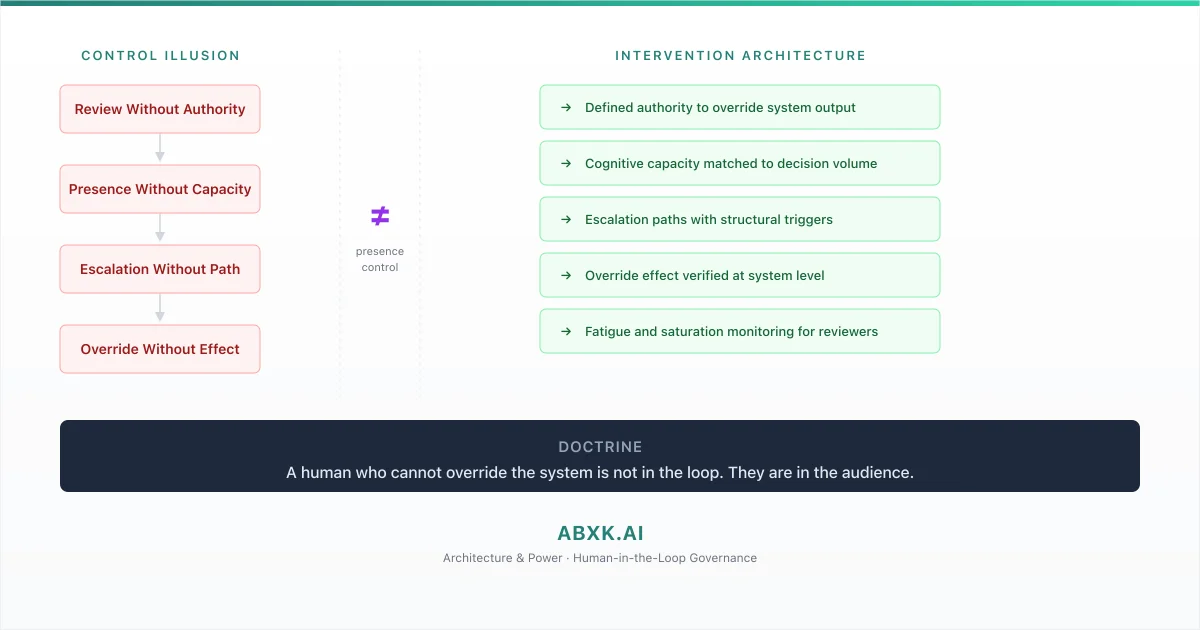
The human is in the loop. The human has no control.
This is not an oversight gap. It is a governance architecture failure. Human-in-the-loop is treated as a control strategy when it is, at most, a design pattern. Control requires architecture — defined authority, matched capacity, structured escalation, and verified override effect. Without that architecture, the human reviewer is a compliance artifact, not a governance mechanism.
AI Governance exists to define how human judgment integrates with automated decision-making under structural accountability. Without intervention architecture, AI Risk Management, AI Security, and AI Compliance produce documentation that describes human oversight while the system operates without meaningful human control.
Human-in-the-loop does not fail at the staffing layer. It fails at the architecture layer — where no one designed the structural conditions required for human intervention to function.
Technical Foundations: Why AI System Dynamics Overwhelm Human Review
The structural mismatch between AI system operation and human cognitive capacity is not incidental. It is inherent in the design characteristics of production AI systems. Understanding this mismatch reveals why human-in-the-loop cannot function as a control strategy without explicit architectural support.
Decision velocity is the foundational constraint. Production AI systems generate outputs at computational speed — hundreds, thousands, or millions of decisions per unit of time. Human cognitive processing operates at biological speed — a reviewer can thoughtfully evaluate a limited number of complex decisions per hour before fatigue degrades judgment quality. The ratio between system output velocity and human review capacity is not a gap. It is a structural incompatibility. No staffing model resolves it because the mismatch is measured in orders of magnitude, not percentages.
Output complexity compounds the velocity problem. AI systems produce outputs through processes that human reviewers cannot reconstruct from the output alone. A risk score of 0.73 does not carry information about which features drove it, how sensitive it is to input perturbation, or whether the model is operating within its valid range. The reviewer sees a number. The number’s meaning depends on calibration, distribution, and operational context that the reviewer does not have access to. The review is structurally superficial — not because the reviewer is incompetent, but because the information required for meaningful evaluation is not available at the review interface.
Calibration opacity means the reviewer cannot assess the reliability of what they are reviewing. A confidence score that appears authoritative may reflect a well-calibrated model operating within distribution or a poorly calibrated model producing arbitrary numerical values. The reviewer has no mechanism to distinguish between the two. Without calibration transparency, the human reviewer is asked to evaluate an output whose statistical meaning is unknown to them.
Automation bias operates as a cognitive force that systematically undermines review effectiveness. When a human reviewer is presented with an AI-generated recommendation alongside the option to accept or reject, the cognitive default is acceptance. The system has processed more data than the reviewer can consider. The system’s output appears precise. The system has performed consistently in the past. Under speed pressure and cognitive load, the reviewer’s judgment converges toward the system’s output — not through deliberate deference but through cognitive efficiency. The review degrades from evaluation to confirmation.
Attention decay under sustained review creates temporal fragility. A reviewer who begins a shift with careful evaluation degrades to pattern-matching within hours. Decision quality does not decline linearly. It declines in stages — from active evaluation to passive scanning to reflexive approval. The governance framework assumes consistent review quality across the entire shift. The cognitive reality produces quality that varies with fatigue, time, and volume.
The technical pattern is consistent: AI system characteristics — velocity, complexity, opacity, and automation bias dynamics — create structural conditions under which human review cannot function as control without explicit architectural intervention.
Structural Fragility: Where Human Oversight Assumptions Degrade
Human-in-the-loop arrangements rest on assumptions that appear reasonable at design time and degrade systematically under production conditions.
The first assumption is sustained attention. Organizations design review workflows assuming that human reviewers will maintain consistent attention across their review period. Cognitive science establishes that sustained attention to repetitive tasks degrades within minutes, not hours. AI review workflows that present similar-looking outputs in rapid succession accelerate attention decay. The reviewer remains present. Their effective evaluation capacity diminishes with each reviewed item.
The second assumption is independent judgment. Organizations assume that human reviewers exercise independent judgment — that they evaluate each AI output on its merits rather than anchoring to the system’s recommendation. In practice, the system’s output functions as a cognitive anchor. The reviewer’s judgment is structurally biased toward the system’s recommendation before the review begins. This is not a character flaw. It is a documented cognitive pattern that intensifies under speed pressure, volume, and institutional signals that the system is reliable.
The third assumption is authority effectiveness. Organizations assign reviewers the authority to override AI outputs. But authority without operational effect is ceremonial. If a reviewer rejects an AI recommendation, does the system modify its behavior? Does the rejection trigger investigation into why the system produced an inappropriate output? Does the rejection feed back into model improvement? In most production systems, the override is applied to the individual case. The system continues to produce the same type of output. The reviewer must override the same pattern repeatedly. Authority without systemic effect produces individual corrections without governance improvement.
The fourth assumption is escalation availability. Organizations assume that when a reviewer encounters an output they cannot evaluate — an edge case, an ambiguous result, a potential system malfunction — escalation is available. In practice, escalation paths are often undefined, undocumented, or inaccessible at operational speed. The reviewer faces an uncertain output with no structured mechanism to pause the system, consult expertise, or elevate the decision. The default action is to approve — not because approval is warranted, but because the alternative is operational delay with no defined process to support it.
The reviewer remains. The conditions for effective review erode. The loop exists in name. Control exists in documentation.
Organizational Failure Patterns
Organizations do not deliberately design ineffective human oversight. They implement human-in-the-loop as a reasonable-seeming control mechanism and discover — usually after an incident — that it provided the appearance of control without the structural foundation.
The most pervasive failure pattern is compliance-driven placement. Organizations place humans in review loops because compliance frameworks require human oversight, not because the review architecture has been designed for effectiveness. The human is present because a policy requires it. The structural conditions for effective review — authority, capacity, information, escalation — are not part of the compliance requirement. The organization satisfies the policy. The system operates without effective control.
The second failure pattern is volume saturation. Organizations design review workflows for expected volume and discover that production volume exceeds design assumptions. A reviewer designed to evaluate fifty cases per day is presented with five hundred. The reviewer adapts — not by reviewing more carefully, but by reviewing more quickly. Review time per case compresses. Evaluation depth decreases. Approval rates increase. The system’s error rate does not change. The reviewer’s detection rate collapses. The loop continues. The control does not.
The third failure pattern is expertise mismatch. The human reviewer lacks the domain expertise or technical knowledge to evaluate the AI system’s output. A compliance reviewer with regulatory expertise but no statistical background cannot assess whether a model’s output reflects genuine risk or calibration artifact. A technical reviewer with statistical expertise but no domain knowledge cannot assess whether the model’s output is operationally appropriate. Effective review requires both. Organizations frequently assign review authority to individuals who possess one competence but not the other.
The fourth failure pattern is override futility. A reviewer overrides an AI output. The override applies to the individual case. The system processes the next input identically. The same type of output appears again. The reviewer overrides again. The pattern repeats indefinitely. The reviewer is exercising authority. The authority has no systemic effect. The system does not learn from overrides. The governance framework does not investigate patterns in overrides. The reviewer’s labor produces individual corrections that never aggregate into system improvement.
The fifth failure pattern is accountability displacement. When an AI system produces a harmful outcome that was reviewed by a human, the organization attributes the failure to the reviewer — the human should have caught the error. This attribution displaces accountability from the governance architecture that failed to provide the reviewer with the authority, information, and structural support required for effective review. The individual is blamed. The architecture is preserved. The failure repeats.
These are governance architecture failures — not performance failures of individual reviewers.
AI Security Implications
Human-in-the-loop arrangements create security exposure when the human element provides the appearance of security control without the structural capability to detect or respond to security-relevant events.
Adversarial inputs designed to evade AI detection systems are also designed to evade the human reviewers who oversee those systems. An adversarial perturbation that manipulates a model’s output is crafted to produce a result that appears normal to the human reviewer. The reviewer sees an output within expected range. The reviewer approves. The adversarial input has passed through both the automated and human layers because the adversary optimized against both.
Review fatigue creates a predictable window of vulnerability. An adversary who understands the volume dynamics of a review workflow can time attacks to coincide with periods of maximum reviewer fatigue — late shifts, high-volume periods, or post-incident surges when review backlogs accumulate. The security control degrades on a predictable schedule. The adversary exploits the schedule.
Override-without-investigation creates a security blind spot. When reviewers override AI outputs without triggering investigation into why the system produced the overridden output, adversarial manipulation of the system may be corrected at the individual case level while the underlying compromise remains undetected. The reviewer catches the symptom. The cause persists. The adversary adjusts and continues.
Where decision authority remains undefined across system layers — as examined in the governance architecture briefing — the human reviewer inherits that authority vacuum. The reviewer is positioned as a security checkpoint but holds no structural authority to halt the system, investigate anomalies, or trigger security response. The reviewer is in the security loop. They are not part of the security architecture.
Compliance and Accountability Implications
Compliance frameworks frequently require human oversight of automated decisions. The requirement creates an institutional incentive to place humans in review loops without designing the structural conditions for those reviews to be effective. The compliance obligation is satisfied. The governance objective is not.
Auditability of human review requires more than documenting that a human reviewed an AI output. Meaningful audit must assess whether the reviewer had the information, authority, and cognitive capacity to conduct an effective review at the time of the review. A timestamp and a username do not demonstrate effective oversight. They demonstrate presence. Presence without capability is not a control that an audit should validate.
Accountability for reviewed AI decisions creates a structural paradox. If the human reviewer approved an AI output that caused harm, is the reviewer accountable? The reviewer was present in the loop. But the reviewer lacked the information to evaluate the output, the authority to investigate anomalies, the escalation path to halt the system, and the operational support to sustain attention across hundreds of similar reviews. Assigning accountability to a reviewer who lacked the structural conditions for effective review is not governance. It is displacement.
Proportionality of human oversight must be assessed against the actual effectiveness of the review, not its formal existence. A review process that rubber-stamps AI outputs at a ninety-eight percent approval rate is not proportionate oversight — it is automated processing with an observational step. Compliance frameworks that accept the existence of review without evaluating its effectiveness produce compliance records that describe a control that does not function.
Compliance is operational enforceability — not the documented presence of a reviewer in a workflow.
Production-Environment Reality
Production environments expose human-in-the-loop failures through operational dynamics that intensify as systems scale, integrate, and accelerate.
Volume scaling creates cognitive saturation. As AI systems process more data and generate more outputs, the review queue grows. Hiring additional reviewers addresses volume but introduces consistency challenges — different reviewers apply different judgment standards to the same types of outputs. Scaling review through staffing does not scale the governance architecture. It replicates individual judgment without structural standardization.
Hybrid workflows that combine automated and manual steps create handoff points where context is lost. The AI system produces an output with internal context — feature importance, confidence distribution, model version. The review interface presents a simplified view — a recommendation and a confidence score. The reviewer evaluates the simplified view. The context required for meaningful evaluation was lost at the handoff. The review is structurally incomplete because the workflow architecture does not transmit the information the reviewer needs.
Model versioning introduces review calibration drift. A reviewer who has developed intuition for a model’s behavior based on months of reviewing its outputs faces a model update that changes the output distribution. The reviewer’s calibrated intuition no longer matches the model’s behavior. Their review effectiveness degrades until they recalibrate — a process that takes time and produces errors during the transition. No governance framework typically manages reviewer recalibration across model versions.
Integration pressure compresses review time. When AI systems are embedded in time-sensitive workflows — real-time processing, customer-facing applications, operational decision chains — the time available for human review is constrained by downstream dependencies. The reviewer must decide within seconds, not minutes. Review quality under time constraint converges toward automatic approval. The loop exists. The review does not.
Vendor-provided AI systems may offer human review interfaces that are designed for operational efficiency rather than governance effectiveness — presenting minimal information, defaulting to approval, and measuring reviewer performance by throughput rather than accuracy. The review interface shapes reviewer behavior. An interface designed for speed produces fast reviews, not thorough ones.
Governance Architecture for Human Intervention
Human-in-the-loop governance requires intervention architecture — structural design that ensures human review functions as control, not ceremony.
Override authority with verified effect. Human reviewers must possess defined authority to override AI outputs. The override must produce verified system-level effect — not just individual case correction. Override patterns must be monitored and must trigger systemic investigation.
Cognitive capacity planning. Review workload must be designed around sustainable human attention thresholds — not system output volume. When system volume exceeds sustainable review capacity, the governance response is flow control, not reviewer acceleration.
Information architecture for review. The review interface must present the information required for meaningful evaluation — not a simplified summary designed for operational speed. Calibration data, confidence distributions, feature indicators, and model version context must be accessible at the review point.
Escalation architecture. Defined triggers must exist for escalation — conditions under which the reviewer pauses the system and elevates the decision to a higher authority. Escalation must be structurally supported, not dependent on individual initiative.
Fatigue and saturation monitoring. Reviewer effectiveness must be monitored for cognitive degradation — through review time patterns, approval rate shifts, and override frequency changes. Governance must respond to saturation signals, not wait for incidents.
Override feedback integration. Reviewer overrides must feed back into model evaluation and governance review. A pattern of overrides on a specific output type must trigger investigation into why the model produces that output — not simply repeated correction.
Reviewer calibration management. When models are updated, reviewers must be recalibrated — informed of changed output characteristics and supported through the transition period. Governance must track reviewer calibration status across model versions.
Intervention validation. The governance framework must periodically validate that human intervention actually changes outcomes — that the review process produces measurably different results than fully automated processing. If it does not, the review is ceremony.
This framework does not eliminate review failure. It prevents review failure from becoming institutional failure.
Doctrine Closing
Human-in-the-loop is not a control strategy. It is a governance architecture requirement.
Organizations that place humans in review workflows without designing intervention architecture produce the appearance of oversight without the structural capability to intervene. The reviewer is present. The reviewer cannot meaningfully control the system. The loop exists. The control does not.
A human who cannot override the system is not in the loop. They are in the audience. Governance architecture exists to ensure that every human positioned as a control mechanism holds the authority, capacity, information, and structural support required to actually control.