The Illusion of Explainability in Enterprise AI
Enterprise AI systems increasingly produce outputs that influence consequential decisions — risk assessments, contract evaluations, resource allocations, compliance determinations. When these decisions are challenged, organizations reach for explainability: a mechanism that purports to describe why the system produced a given output.
The explanation appears. The accountability question appears resolved. It is not.
Explainability in production AI systems is not what most organizations believe it to be. It is not a faithful reconstruction of the system’s decision process. It is a post-hoc approximation — a simplified narrative generated after the decision has already been made, using methods that describe plausible reasoning rather than actual computational causality.
This distinction is not academic. It is structural.
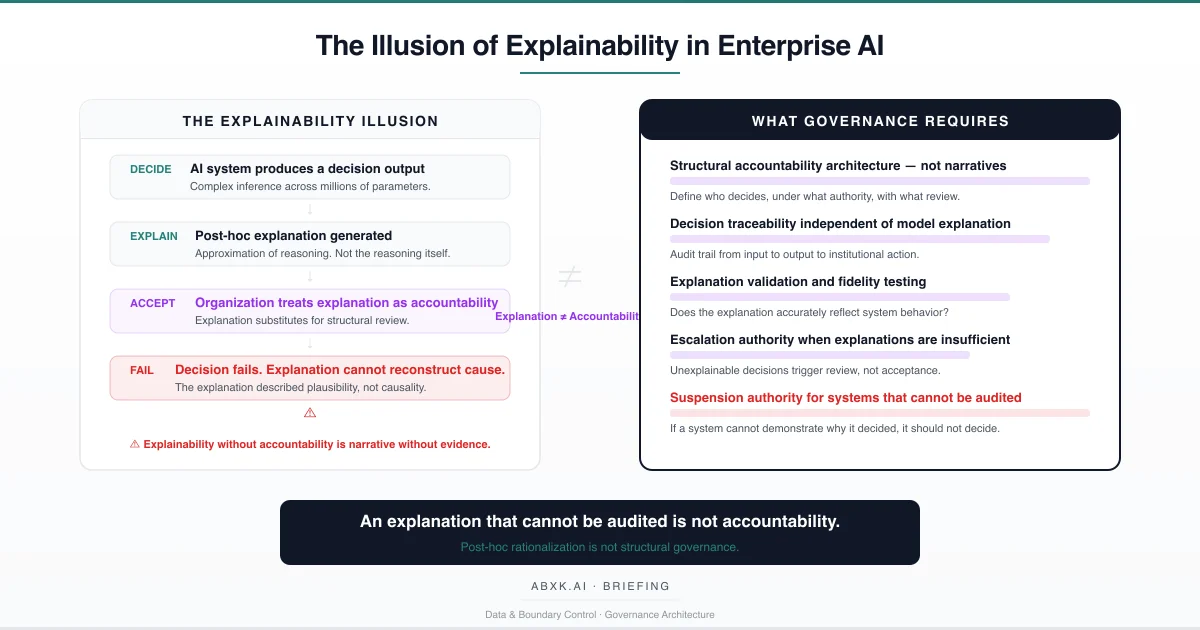
When organizations treat explanation as accountability, they create a governance architecture that appears complete but cannot withstand audit, cannot reconstruct failure, and cannot attribute responsibility. The system produces an output. The explanation produces a narrative. Neither produces the structural traceability that governance requires.
Explainability does not fail at the technical layer. It fails at the accountability layer — where organizations mistake narrative plausibility for decision-layer governance.
Understanding that distinction is central to AI Risk Management, AI Security, AI Compliance, and Responsible AI implementation in production environments.
Technical Foundations: What Explanations Actually Produce
AI systems — particularly deep learning models, ensemble methods, and generative architectures — operate through computational processes that do not produce human-interpretable reasoning as a byproduct of inference. The model processes inputs through layers of mathematical transformations, weight multiplications, and activation functions. The output emerges from the aggregate interaction of millions or billions of parameters. No single parameter or pathway constitutes “the reason” for a given output.
Explainability methods attempt to bridge this gap through approximation. They do not expose the model’s actual reasoning. They generate simplified representations of what the model appears to have weighted.
Feature attribution methods assign importance scores to input features, suggesting which variables contributed most to the output. These scores are computed through perturbation analysis, gradient calculation, or surrogate modeling. They describe statistical sensitivity, not causal reasoning. A feature identified as important may correlate with the output without causing it. The explanation is correct about correlation. It is silent about mechanism.
Surrogate models replace the complex model with a simpler, interpretable approximation — typically a linear model or decision tree fitted to the original model’s outputs within a local region of the input space. The surrogate is interpretable. It is also a different model. Its explanations describe the surrogate’s behavior, not the original model’s behavior. The fidelity of this approximation depends on the complexity of the original model’s decision surface in the relevant region. In high-dimensional spaces with non-linear interactions, local fidelity guarantees are weak.
Attention visualization in transformer architectures displays which input tokens received the highest attention weights during processing. This is frequently presented as evidence of what the model “focused on.” Attention weights reflect computational flow, not semantic reasoning. High attention on a particular token does not mean the model used that token in the way a human would interpret the explanation. The visualization is compelling. The interpretive framework is unreliable.
Counterfactual explanations describe what would need to change in the input for the output to differ. These are useful for identifying decision boundaries but do not explain why the boundary exists where it does. They describe the model’s behavior at specific points without revealing the structural logic that produced that behavior.
Each method produces an approximation. None produces the actual reasoning chain. The explanation is always a reconstruction — and the distance between reconstruction and reality is unmeasured, unmonitored, and in most deployments, unacknowledged.
Structural Fragility: Where Explainability Breaks
Explainability methods carry implicit assumptions that degrade under production conditions. The degradation is silent. The explanations continue to appear coherent even when their fidelity to actual model behavior has eroded.
The first assumption is model stability. Explainability methods are validated — when they are validated at all — against the model at a specific point in time. When the model is updated, retrained, or fine-tuned, the relationship between the model’s behavior and the explanation method’s approximation changes. The explanation method is not retrained with the model. Its fidelity to the updated model is unknown. The explanation continues to produce output. Its accuracy is no longer verified.
The second assumption is input distribution consistency. Explanation methods produce reliable approximations within the distribution of data they were designed for. When production inputs drift beyond the training distribution — through changing user behavior, evolving data sources, or novel input patterns — the explanation method’s approximations may no longer reflect the model’s actual behavior in the shifted region. The model produces an output in unfamiliar territory. The explanation describes that output using assumptions from familiar territory.
The third assumption is explanation completeness. Feature attribution methods identify which features were most important. They do not identify which features were ignored, which interactions between features influenced the output, or which features would have changed the outcome if they had been different. The explanation presents a partial view. Organizations treat it as a complete view. The gap between partial and complete is where accountability fails.
The fourth assumption is consumer competence. Explanations are consumed by humans — analysts, reviewers, auditors, executives — who interpret them through their own cognitive frameworks. When an explanation says “Feature X was the most important factor,” the consumer interprets importance through a domain-specific lens that may not align with the statistical meaning of importance in the explanation method. The explanation is technically accurate. The interpretation is structurally misleading.
The number remains. The meaning changes. The explanation does not update.
Organizational Failure Patterns
Organizations adopt explainability as a governance mechanism because it appears to solve the accountability problem. It does not solve it. It defers it.
The most common failure pattern is explanation as compliance substitute. Organizations deploy explainability tools and document their availability in compliance frameworks. When auditors ask how the system reaches decisions, the organization presents explanations. The auditor sees a plausible narrative. The structural question — whether the explanation faithfully represents the model’s actual behavior — is never asked because the narrative is sufficiently convincing. Compliance is satisfied by plausibility, not by fidelity.
The second failure pattern is explanation as review replacement. Organizations route AI outputs through human reviewers and provide explanations to support the review process. The reviewer reads the explanation, finds it plausible, and approves the output. The review becomes an exercise in narrative acceptance rather than independent judgment. The explanation, designed to be persuasive and comprehensible, functions as an automation bias amplifier — making the reviewer more likely to accept the output than they would without the explanation. The presence of explainability reduces governance rigor rather than increasing it.
The third failure pattern is explanation as incident defense. When an AI system produces a harmful outcome, the organization retrieves the explanation generated at the time of the decision and presents it as evidence of reasonable process. The explanation shows which features were weighted. It does not show why those weights produced the harmful outcome, whether the model was operating within its valid distribution, whether the explanation itself was faithful to the model’s behavior, or whether anyone with appropriate authority reviewed the output before it became consequential. The explanation defends the process. It does not explain the failure.
The fourth failure pattern is explanation scope limitation. Organizations implement explainability for the model layer — the inference engine that produces the output — while ignoring the broader decision chain. The data that entered the model, the transformations it underwent, the business rules that modified the output, the workflow that acted on it — these elements are outside the explanation scope. The model’s behavior is partially explained. The decision’s outcome remains structurally unaccountable.
These are governance failures — not explainability failures. The tools produce what they are designed to produce: approximations. The failure is organizational — treating approximation as accountability.
AI Security Implications
Explainability creates security exposure through two mechanisms: it reveals model behavior to adversaries, and it provides false assurance to defenders.
Explanations that describe which features drive model decisions provide adversaries with a map of the model’s decision surface. Feature attribution reveals what the model is sensitive to. Counterfactual explanations reveal where decision boundaries lie. Attention visualizations reveal what the model focuses on. Each explanation method, when accessible to adversaries, reduces the cost of crafting adversarial inputs that exploit the model’s structure.
The security paradox is structural: the more transparent the explanation, the more useful it is to adversaries. Organizations that publish explanations for transparency or compliance purposes simultaneously publish attack intelligence. Governance architecture must balance explainability obligations against security exposure — a balance that most deployments do not address because explainability and security are governed by separate teams with separate frameworks.
False assurance is equally dangerous. When security teams receive explanations that describe model behavior in plausible terms, they may assess the model as operating correctly when it is not. An adversarially manipulated input that produces a plausible explanation is more dangerous than one that produces no explanation — because the explanation suppresses the skepticism that would otherwise trigger investigation. The explanation becomes a camouflage layer for adversarial exploitation.
Where data lineage is absent, explanations operate on unverifiable foundations. An explanation that attributes a decision to specific features cannot be validated if the provenance of those features is unknown. The explanation appears complete. The evidentiary basis is structurally absent.
Compliance and Accountability Implications
Compliance frameworks increasingly require organizations to explain automated decisions. This requirement creates a structural risk: organizations may satisfy the requirement’s form while failing its intent.
The intent of explainability requirements is accountability — ensuring that organizations can identify what happened, why, and who is responsible. The form is explanation — a narrative description of system behavior. When organizations satisfy the form without achieving the intent, compliance documentation accumulates while accountability remains structurally absent.
Auditability requires more than explanation. It requires decision traceability — the ability to reconstruct the complete chain from input data, through processing, to output, to institutional action. Explanation addresses one link in that chain: why the model produced a specific output. It does not address who authorized the input data, whether the model was operating within its validated range, who reviewed the output, who decided to act on it, or who bears responsibility for the outcome. An explainable system that lacks decision traceability is auditable in appearance but unaccountable in structure.
Proportionality assessment cannot rely on explanation alone. Compliance frameworks require that automated decisions are proportionate to their purpose and impact. Assessing proportionality requires understanding not just what the model weighted but what data it consumed, what alternatives existed, and what safeguards were in place. Explanation provides the model’s perspective. Proportionality requires the governance perspective.
Documentation of explanations creates a false compliance record when explanation fidelity is not validated. Organizations that document explanations without testing whether those explanations accurately represent model behavior create audit trails that describe a system the organization believes exists rather than the system that actually operates. The documentation is thorough. The foundation is unverified.
Compliance is operational enforceability — not documentation. Explainability that cannot be audited for accuracy is documentation without evidentiary value.
Production-Environment Reality
Production environments degrade explanation fidelity through operational patterns that are individually unremarkable and collectively corrosive.
Transformation chains between model output and institutional action introduce decision steps that explanations do not cover. A model produces a risk score with an explanation. A business rule modifies the score. A workflow routes the modified output to a decision-maker. The decision-maker acts. The explanation describes the model’s original output. The institutional action reflects the modified, routed, and interpreted version. The gap between explanation and action grows with each transformation step.
Hybrid workflows that combine AI outputs with human judgment create accountability ambiguity that explanations cannot resolve. When a human modifies an AI output based on domain expertise, the resulting decision reflects both the model’s inference and the human’s judgment. The explanation covers the model’s contribution. The human’s reasoning is undocumented. Accountability for the combined output is structurally undefined.
Model versioning creates temporal explanation gaps. A model version produces an output with an explanation. The model is updated. The explanation method is not recalibrated. Explanations for the new model version use approximation parameters calibrated to the old version. The explanation appears valid. Its fidelity to the current model is unverified.
Monitoring obligations require explanation validation that most organizations do not implement. Organizations monitor model performance through accuracy metrics, drift detection, and bias assessment. They rarely monitor explanation fidelity — whether the explanations generated today accurately reflect the model’s current behavior. Explanation monitoring requires comparing explanation outputs against independent analysis of model behavior. This comparison is computationally expensive and methodologically complex. It is deferred.
Integration pressure compresses explanation review. When business processes depend on rapid AI output consumption, explanations are generated but not examined. The explanation exists. No one reads it. The governance mechanism functions formally but provides no actual oversight.
Vendor policy evolution affects explanation availability and methodology without organizational control. When a vendor changes its explanation approach, updates its attribution method, or modifies its explanation granularity, the organization’s governance framework — which was calibrated to the previous explanation output — becomes misaligned. The explanation changes. The governance framework does not.
Governance Architecture for Explainability
Explainability governance requires treating explanation as one component of accountability — not as accountability itself.
Structural accountability architecture. Decision authority, review processes, escalation paths, and suspension criteria must be defined independently of explanation capability. Accountability exists at the governance layer. Explanation supports it. Explanation does not replace it.
Decision traceability independent of model explanation. Every AI-influenced decision must be traceable from input data, through model inference, through post-processing, through human review, to institutional action. This traceability must exist whether or not the model provides an explanation. Lineage and traceability are governance infrastructure. Explanation is a supplementary output.
Explanation fidelity testing. Organizations must validate that explanations accurately reflect model behavior. This requires periodic comparison of explanation outputs against independent analysis — perturbation testing, counterfactual verification, or surrogate model fidelity assessment. Explanation methods that have not been validated against the current model version are treated as unverified.
Explanation scope documentation. Every explanation mechanism must document what it covers and what it does not. Feature attributions that do not account for feature interactions must state that limitation. Surrogate models must document their fidelity boundaries. Attention visualizations must acknowledge the gap between attention weights and semantic reasoning. Consumers of explanations must understand the explanation’s boundaries.
Escalation authority for unexplainable outputs. When a system produces outputs that cannot be adequately explained — because the model’s behavior falls outside the explanation method’s valid range — defined authority must exist to escalate the decision, defer the action, or suspend the system. Unexplainability is not an edge case to be ignored. It is a governance signal to be acted upon.
Suspension authority for unauditable systems. When explanation fidelity cannot be verified, when explanation scope is insufficient for accountability requirements, or when explanation methods have not been revalidated after model updates, defined authority must exist to suspend the system’s decision-making role until accountability can be structurally demonstrated.
This framework does not eliminate explanation error. It prevents explanation error from becoming institutional failure.
Doctrine Closing
Explainability is not an accountability architecture. It is a narrative mechanism that approximates model behavior without guaranteeing fidelity, without covering the full decision chain, and without replacing the structural governance that accountability requires.
An explanation that cannot be audited is not accountability. It is institutional comfort without evidentiary foundation.
Governance does not make AI systems transparent. It makes the decisions those systems influence traceable, attributable, and survivable — regardless of whether the model can explain itself.
Explainability is not a governance solution. It is a governance input. The architecture that surrounds it determines whether accountability exists or merely appears to.