When AI Systems Redefine Data Boundaries
Organizations define data boundaries. They establish which data resides in which systems, who has access, under what conditions data may be shared, and what controls govern movement between environments. These boundaries form the structural foundation of data governance.
AI systems operate across those boundaries. They consume data from multiple sources, combine it through inference, and produce outputs that carry input data — directly or embedded in derived insights — into systems, workflows, and decision processes that were never part of the original data governance scope.
This is not a data leakage problem in the traditional sense. The data does not escape through a vulnerability. It propagates through designed functionality. The AI system is operating as intended. The data boundary erosion is a structural consequence of that operation.
Data boundary governance fails in AI environments because it was designed for static architectures — environments where data resides in defined locations and moves through controlled channels. AI systems introduce dynamic data flows that create new pathways, new combinations, and new exposure surfaces with every inference cycle. The boundaries defined at deployment do not reflect the boundaries that exist in production.
Data boundary failure in AI systems does not occur at the perimeter layer. It occurs at the architecture layer — where systems designed to integrate, infer, and propagate were deployed inside governance frameworks designed for containment.
Understanding that distinction is central to AI Risk Management, AI Security, AI Compliance, and Responsible AI implementation in production environments.
Technical Foundations: How AI Systems Move Data Beyond Boundaries
AI systems interact with data in ways that fundamentally differ from traditional information systems. Understanding these mechanisms reveals why conventional boundary controls are structurally insufficient.
Cross-source inference creates implicit data movement. When an AI system ingests data from multiple sources and produces an output that reflects combined patterns across those sources, the output contains information derived from all contributing datasets. A risk assessment that combines financial data, behavioral data, and operational data produces an output that implicitly carries elements from each source. The output enters downstream systems. The governance restrictions that applied to each individual data source do not follow the combined output because the output is classified as a new data element — not as a derivative of restricted sources.
Embedding and representation learning dissolve source-level boundaries. When data is transformed into vector embeddings, latent representations, or model weights, the boundary between distinct data sources disappears at the representation layer. A model trained on customer data, operational data, and third-party data produces a unified representation where individual source boundaries are mathematically irrecoverable. The model’s outputs reflect all sources simultaneously. Source-specific access controls cannot be applied to outputs because the source distinction no longer exists in the model’s representation.
Retrieval-augmented systems create dynamic boundary crossings. Systems that retrieve information from document stores, knowledge bases, or external sources at inference time create data flows that vary with each query. A query that retrieves a restricted document and incorporates its content into a response has moved restricted data into the response stream. The next query may retrieve different documents, creating different boundary crossings. The boundary architecture must account for dynamic, query-dependent data flows — a requirement that static perimeter controls cannot satisfy.
Output propagation chains extend boundary exposure incrementally. An AI system produces an output. That output feeds into another system as input. The second system produces its own output incorporating the first system’s data. Each propagation step moves the original data further from its governed boundary. After three or four propagation steps, the data’s origin is untraceable, its governance constraints are unknown, and its presence in the receiving system is undocumented.
Personalization and adaptation systems create per-user boundary violations. Systems that learn from individual user behavior accumulate data about that user across interactions. When that learned behavior influences outputs presented to other users — through collaborative filtering, pattern-based recommendations, or aggregated insights — individual user data has crossed a boundary from personal scope to collective scope. The boundary violation is distributed across millions of micro-interactions. No single event triggers detection.
The technical pattern is consistent: AI systems are designed to integrate, combine, and propagate. Data boundaries are designed to contain, separate, and restrict. These architectures are structurally incompatible. The AI system wins. The boundary erodes.
Structural Fragility: Where Boundaries Break
Data boundary governance in AI environments rests on assumptions that appear sound at deployment and degrade systematically under production conditions.
The first assumption is boundary awareness. Organizations assume they know where their data boundaries are. In traditional systems, this is largely true — data resides in databases, files, and applications with defined perimeters. In AI systems, data boundaries include every system the AI reads from, every system its outputs flow into, every model that was trained on the data, and every downstream process that consumes AI-generated content. The actual boundary surface is orders of magnitude larger than the documented boundary surface.
The second assumption is output neutrality. Organizations treat AI outputs as new data elements that do not inherit the governance constraints of their inputs. A risk score generated from restricted financial data is treated as a score — not as a derivative of restricted data. A summary generated from confidential documents is treated as a summary — not as confidential content in compressed form. This assumption enables boundary dissolution because outputs carry input data in transformed representations that governance frameworks do not recognize as boundary-relevant.
The third assumption is integration containment. Organizations design integrations with defined data flows — System A sends specific data to System B through a controlled interface. AI systems create emergent integrations that were not designed. A model trained on data from System A produces outputs that influence decisions in System C through a workflow that passes through System B. The integration was never designed. The data flow was never governed. The boundary was never defined for this pathway because no one anticipated it would exist.
The fourth assumption is temporal boundary stability. Organizations define data boundaries at a point in time and treat them as durable. AI systems evolve their data consumption patterns as models are updated, retrieval databases are expanded, and integration points multiply. The boundary defined at deployment reflects the system’s initial state. The boundary that exists after twelve months of production operation may include data sources, output destinations, and propagation paths that did not exist at deployment.
The number remains. The meaning changes. The boundary shifts.
Organizational Failure Patterns
Organizations do not intend to lose control of data boundaries. They deploy AI systems within documented governance frameworks and discover — often through incidents rather than monitoring — that the boundaries they documented no longer reflect operational reality.
The most common failure pattern is scope creep without governance extension. An AI system is deployed with a defined data scope — specific sources, specific uses, specific outputs. Over time, the system is connected to additional data sources, its outputs are consumed by additional processes, and its integration surface expands. Each expansion is individually approved as a feature enhancement or operational optimization. No expansion triggers a boundary governance review because each is classified as a minor change. The cumulative effect is a system operating across boundaries that no governance review has evaluated.
The second failure pattern is output misclassification. Organizations classify AI outputs based on the output’s format or function — a recommendation, a score, a summary, a prediction — rather than based on the data the output contains or derives from. A summary of restricted documents is classified as “a summary” and routed to systems authorized to receive summaries but not authorized to receive restricted document content. The classification is correct about format. It is wrong about data governance.
The third failure pattern is inference-chain blindness. Organizations monitor direct data flows — System A to System B — but do not monitor indirect flows through inference chains. Data from System A trains a model. The model produces outputs consumed by System B. System B uses those outputs to generate reports consumed by System C. The data governance team sees no direct connection between System A and System C. The inference chain creates a connection that no monitoring system tracks.
The fourth failure pattern is vendor boundary delegation. Organizations use vendor AI services that consume organizational data and produce outputs. The vendor’s internal processing — including intermediate storage, model training, caching, and quality assurance — creates data flows within the vendor’s infrastructure that the organization cannot observe. The organization’s data has crossed its boundary into the vendor’s environment. The vendor’s processing creates additional boundary events within that environment. The organization governs data up to the vendor boundary. Beyond it, boundary governance is the vendor’s responsibility — and vendor governance priorities may not align with organizational requirements.
These are governance failures — not security failures. The data moves through designed functionality, not through vulnerabilities. The boundaries erode through normal operation, not through attack.
AI Security Implications
Data boundary erosion creates security exposure that conventional perimeter-based security architectures do not address.
When data propagates beyond its governed boundary through AI outputs, it enters environments with different security controls, different access permissions, and different threat exposure. Data that was protected by strong access controls in its original system may exist in an AI output stored in a system with weaker controls. The original security posture does not follow the data through the propagation chain. The data’s security level degrades with each boundary crossing.
Cross-system propagation creates lateral movement pathways for adversaries. An attacker who compromises a low-security system that receives AI outputs may gain access to information derived from high-security systems — information that propagated through AI inference chains. The attacker did not breach the high-security system. The AI system moved the data to a location the attacker could reach. The boundary erosion created the attack pathway.
Aggregation through AI inference creates sensitivity escalation. Individual data elements that are individually non-sensitive may become sensitive when combined through AI inference. A customer’s purchase history is mildly sensitive. Combined with location data, browsing behavior, and communication patterns through an AI model, the aggregated insight is highly sensitive. The individual data sources were governed at their individual sensitivity levels. The aggregated output exceeds all of them. No boundary control anticipated the sensitivity escalation because no boundary control evaluated the combined output.
Where data lineage is absent, boundary violations are structurally undetectable. An organization cannot determine whether data has crossed a boundary if it cannot trace where the data has been. Lineage and boundary governance are interdependent — lineage provides the visibility that boundary enforcement requires. Without lineage, boundary governance operates on assumptions about data location. Those assumptions may not reflect reality.
The attack surface is not the AI model. The attack surface is the data propagation architecture — and AI systems expand that surface through every inference cycle.
Compliance and Accountability Implications
Compliance frameworks require organizations to maintain control over data — to know where it is, how it is used, who has access, and under what authority it was shared. AI-driven boundary erosion directly undermines each of these requirements.
Data location accountability requires knowing where data resides. When AI outputs carry input data into downstream systems through propagation chains, the organization’s data location inventory becomes incomplete. The data exists in locations that the compliance framework does not document because no one recognized that the AI output constituted a data transfer. The compliance record describes data locations accurately for the original data. It is blind to derivative locations created through AI propagation.
Purpose limitation requires that data is used only for its stated purpose. When data enters an AI system for one purpose and its derivatives propagate into systems serving different purposes, purpose limitation is violated through the propagation mechanism rather than through deliberate misuse. The organization did not decide to use the data for the secondary purpose. The AI system’s output carried it there. Purpose limitation governance that monitors intent does not catch violations that occur through architecture.
Consent management requires tracking what data subjects authorized. When AI systems combine data from multiple consent contexts and produce outputs that carry elements from each, the resulting output may reflect data that was authorized under one consent framework but propagated into a context covered by a different framework. The consent that applied to the original data does not automatically apply to the AI-derived output in the receiving system.
Cross-border data transfer restrictions require knowing when data crosses jurisdictional boundaries. When AI outputs propagate through systems deployed across multiple jurisdictions, data may cross borders embedded in AI outputs that no transfer mechanism governs. The organization’s data transfer impact assessment evaluated direct transfers. It did not evaluate transfers embedded in AI inference outputs routed through multi-jurisdictional infrastructure.
Compliance is operational enforceability — not documentation. Boundary governance that documents static perimeters while AI systems create dynamic propagation paths produces compliance records that describe a controlled environment that no longer exists.
Production-Environment Reality
Production environments accelerate boundary erosion through operational patterns that compound silently.
Transformation chains extend boundary exposure with each processing step. Data enters an AI system, is transformed through inference, exits as output, enters another system as input, is transformed again, and propagates further. Each transformation step creates a new data element that carries information from previous steps without carrying their governance constraints. After multiple transformations, the data’s boundary history is irretrievable.
Hybrid workflows that combine AI outputs with human judgment create boundary events that governance architectures do not classify. When a human analyst incorporates an AI output into a report, the report inherits the data governance obligations of the AI output’s underlying data. But the report is classified as the analyst’s work product, not as a derivative of AI-processed data. The boundary crossing occurs. The classification misses it.
Model versioning affects boundary scope without triggering governance review. When a model is updated to consume additional data sources, the boundary scope expands. The model update is evaluated for performance impact. Its boundary impact — which data now enters the model’s inference chain and where the outputs propagate — is rarely assessed as a governance event.
Monitoring obligations require boundary tracking that most architectures do not provide. Organizations monitor data access, data transfer, and data storage. They do not monitor data propagation through AI inference chains because the monitoring architecture was not designed for derivative data flows. The monitoring covers direct boundary events. It is blind to indirect boundary erosion.
Integration pressure from business operations creates boundary expansions that outpace governance review. New data sources are connected. New output consumers are added. New integration pathways are activated. Each expansion is operationally justified. Cumulatively, they redraw the data boundary in ways that no governance review has evaluated.
Vendor policy evolution affects boundary scope without organizational visibility. When a vendor modifies its data processing practices, updates its model architecture, or changes its output routing, the organization’s data may traverse new pathways within the vendor’s infrastructure. The boundary has been redrawn by the vendor. The organization’s boundary governance reflects the previous configuration.
Governance Architecture for Data Boundary Control
Data boundary governance in AI environments requires dynamic architecture that tracks actual data flows — not static perimeters that describe intended containment.
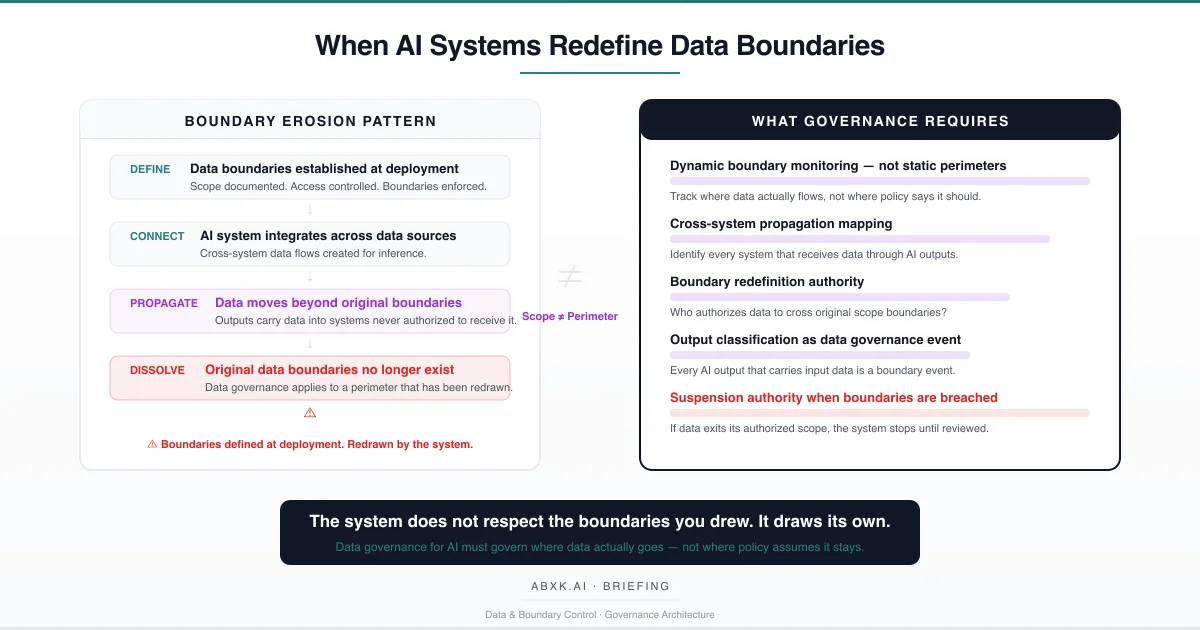
Dynamic boundary monitoring. Organizations must implement monitoring that tracks where data actually flows through AI systems — not where policy documents say it should flow. This monitoring must cover direct data movement, derivative data propagation through AI outputs, and cross-system inference chains.
Cross-system propagation mapping. Every AI system must maintain a documented map of its data sources and output destinations, updated continuously as integrations evolve. This map must include direct consumers and downstream systems that receive data through propagation chains.
Output classification as boundary event. Every AI output that carries, derives from, or is influenced by governed data must be classified as a data boundary event. Output classification must reflect the governance obligations of the underlying data, not merely the format of the output.
Boundary redefinition authority. When AI operations create new data flows that cross existing boundaries, defined authority must exist to evaluate, approve, or reject the boundary change. Boundary redefinition must be an explicit governance decision — not an emergent consequence of system operation.
Sensitivity escalation detection. Monitoring systems must detect when AI inference combines individually lower-sensitivity data into higher-sensitivity outputs. Sensitivity escalation through aggregation must trigger governance review.
Propagation chain limits. Governance architecture must define maximum propagation depth — how many systems an AI output may traverse before requiring re-authorization. Unbounded propagation is unbounded boundary erosion.
Suspension authority for boundary violations. When data is detected outside its authorized boundary through AI propagation, defined authority must exist to suspend the propagation pathway until governance review is complete. Continued propagation after detection is continued boundary erosion under organizational awareness.
This framework does not eliminate boundary erosion. It prevents boundary erosion from becoming institutional failure.
Doctrine Closing
Data boundary governance is not a perimeter problem. It is a governance architecture problem.
Organizations that define data boundaries at deployment and assume those boundaries persist through AI operation govern a system that no longer exists. The boundaries were drawn for static architectures. AI systems operate through dynamic integration, inference, and propagation. The boundaries the organization documented are not the boundaries the system observes.
Governance does not make boundaries permanent. It makes boundary changes visible, authorized, and reversible — so that the organization governs where data actually goes, not where it once assumed data would stay.
The system does not respect the boundaries you drew. It draws its own. Governance exists to ensure that redrawing requires authority.