
Motorsport Racing Calendar 2026
Motorsport racing calendar 2026: F1, WEC, IMSA, DTM, MotoGP and special events — every date, hand-picked, with countdown and recommendation.
Motorsport Intelligence
Powered by AI, data and real-world experience.
Motorsport racing calendar 2026: F1, WEC, IMSA, DTM, MotoGP and special events — every date, hand-picked, with countdown and recommendation.

Motorsport racing series at a glance: F1, WEC, IMSA, DTM and MotoGP — what they are, which classes they run, why they matter and how ABXK ranks them.

Motorsport circuits in the track guide: Le Mans, Nürburgring Nordschleife, Spa, Monza and more — character, sectors, history and what each track demands.
The ABXK Data Hub: dashboards, race intelligence, knowledge graph, comparisons, predictions and tools — motorsport explained through data, connected, searchable, reproducible.
Motorsport AI: AI-driven data analysis of the great 24-hour races — manufacturer pace, reliability, stint strategy, and efficiency, broken down hour by hour and checked against the classifications.
Interactive race dashboards for the great 24-hour races: lap times, tire stints, pit stops, position changes, and the safety-car effect — read the race, don't just follow it.
Le Mans and Daytona, three seasons, the same metrics: what connects WEC and IMSA at 24-hour races — and how both series changed from 2024 to 2026.
Interactive knowledge graph of endurance and motorsport racing: 590 drivers, manufacturers, circuits, series and teams and how they connect — Michael Schumacher, Ferrari, Le Mans, Formula 1 and more. Click, search, explore.
Put two racing drivers or manufacturers side by side: shared teams, series, circuits and connections — derived automatically from the ABXK Motorsport Knowledge Graph.
Forecasts before the big endurance races and an honest review afterward: AI hypothesis against the community tip — the road to the ABXK Race Prediction League.
Head-to-head Hypercar comparisons built from race data — finishing positions, fastest-lap pace and wins at Le Mans and Daytona 2024–2026.
Hypercar performance analysis by the data — every top-class manufacturer at Le Mans and Daytona 2024–2026 ranked by wins, podiums, pace and reliability.
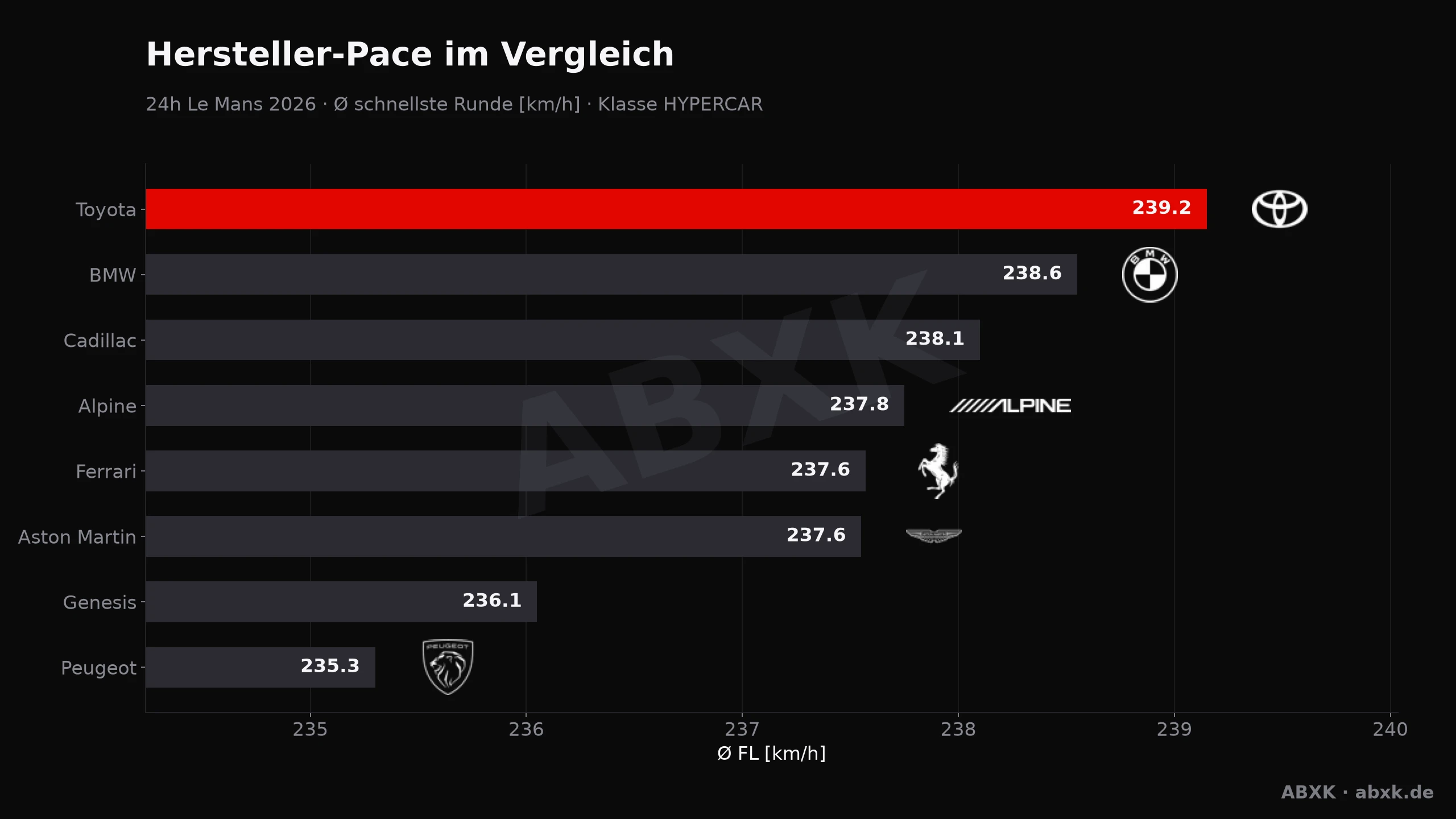
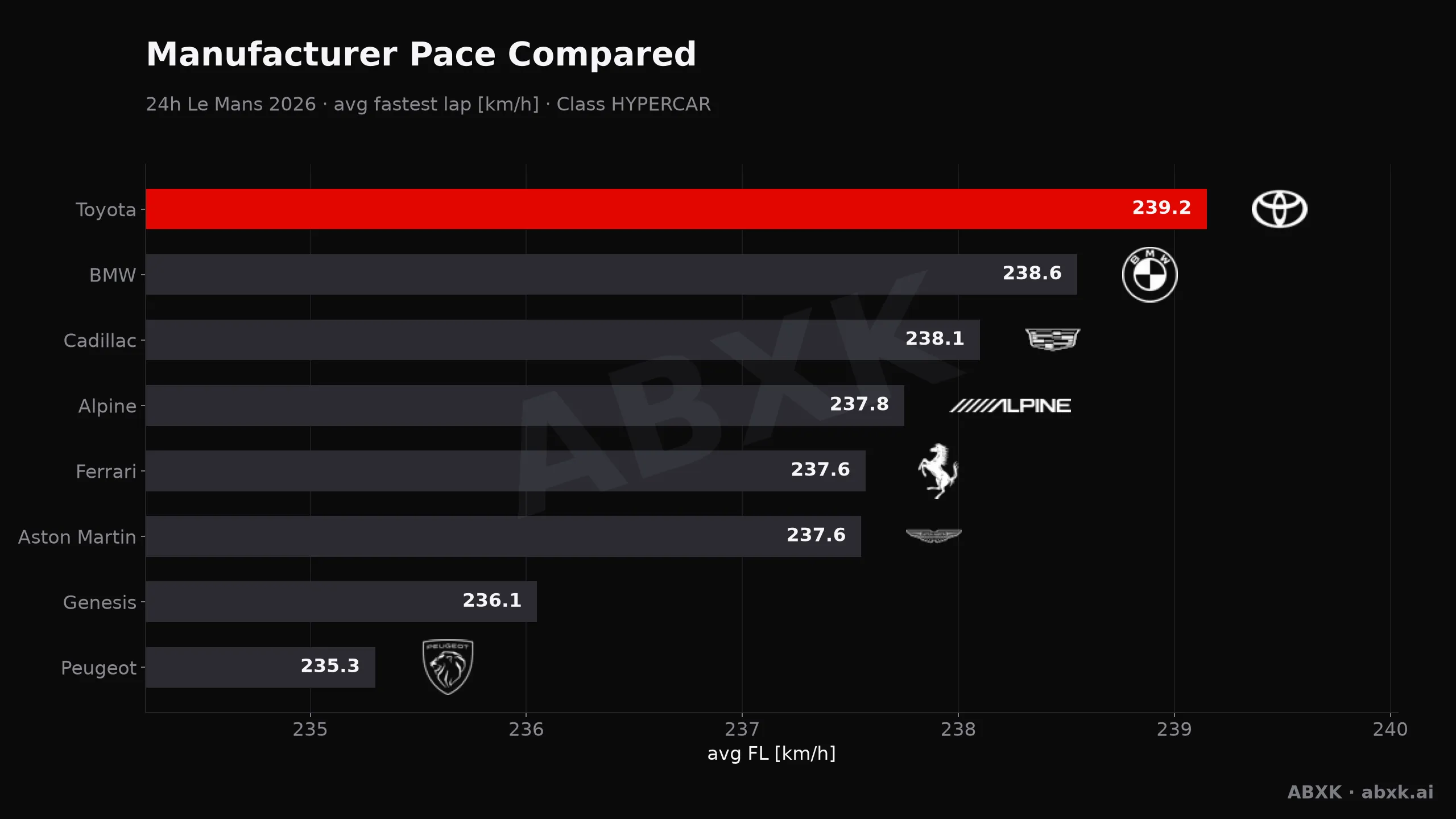
Toyota wins Le Mans 2026 — and for the first time in years is also the fastest car. Manufacturer pace, reliability and the closing phase, analyzed hour by hour.
Porsche didn't race at Le Mans in 2026. What does the data say: could the further-developed 963 have beaten Toyota? A carefully bounded what-if model with clearly stated uncertainties.
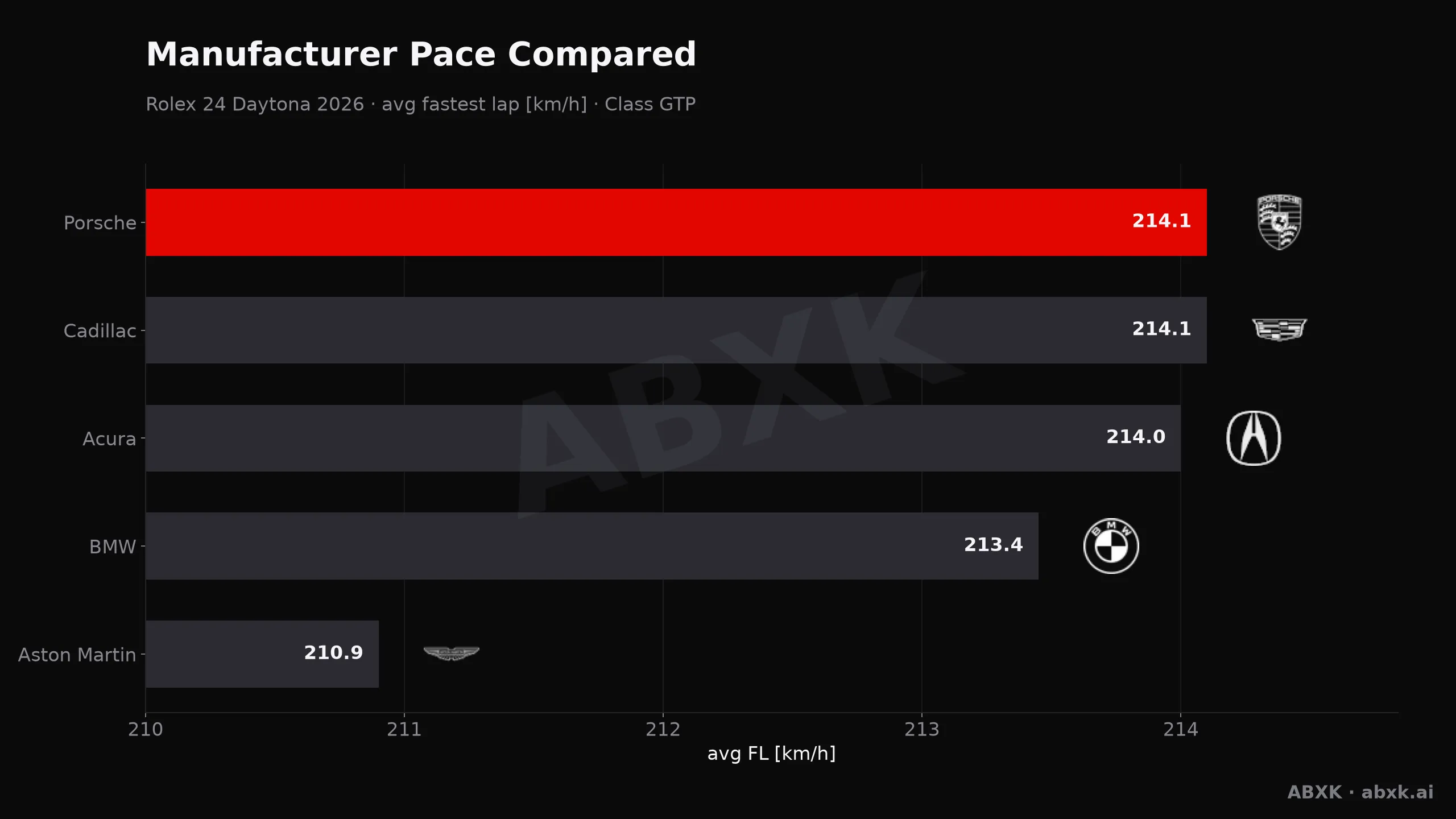
Porsche Penske wins the Rolex 24 for the third straight year — in the series' closest finish yet. Pace, reliability, and race dynamics under the data microscope.
Real formula cars on real circuits. What formula programs deliver, what they cost, who they suit — and which ones ABXK recommends.
View →GT programs beyond experience days. GT4, GT3, Porsche Cup, Ferrari Challenge — what sets the classes apart, what they cost, what they demand.
View →A superbike on a real track. What trackdays on a race bike demand, which schools are worth it, and the mistakes beginners make most often.
View →